For real though: There is a possibility that this is the most epic instance of malicious compliance that has occurred in the history of tech. There is no way a competent engineer would think Reddit would be a good (a primary characteristic of which would be “relatively unpoisoned”) training set. It’s just not possible. This was 100% some business and finance yahoo saying “do the thing” and Eng saying “ok but you’re not going to like it”.
Yeah, I thought Reddit would be a great data set at first because it comes with quality indicators via up/down votes. But, thinking about it more, a) total number of votes is more of a function of how popular the thread is and that comment’s positioning is in that thread, b) comments can get upvoted for accuracy or humour, and in the latter case, many times the humour is specifically about making inaccurate comments. And there’s a bias towards funny. My own most upvoted comments were mostly short funny ones while long thoughtful ones wouldn’t get that much attention. Not that being long or thoughtful implied anything about correctness, because c) different communities had different biases, and d) it was all populist stuff, so something that sounds good but isn’t accurate can outperform something that is accurate but less poetic.
And to drive home how stupid the way we’re currently training approaching AI is, it’s pretty much the equivalent of sticking a kid in front of an internet browser, taking a little while to teach them how to use the browser, then leaving them on their own while they learn everything else they know, including the languages it’s all expressed in.
Instead we have a whole curated education system that takes over a decade. I think AI could reduce that time but it still needs the curation part as well as feedback systems to reinforce correct knowledge and correct bad knowledge.

{kind=link}
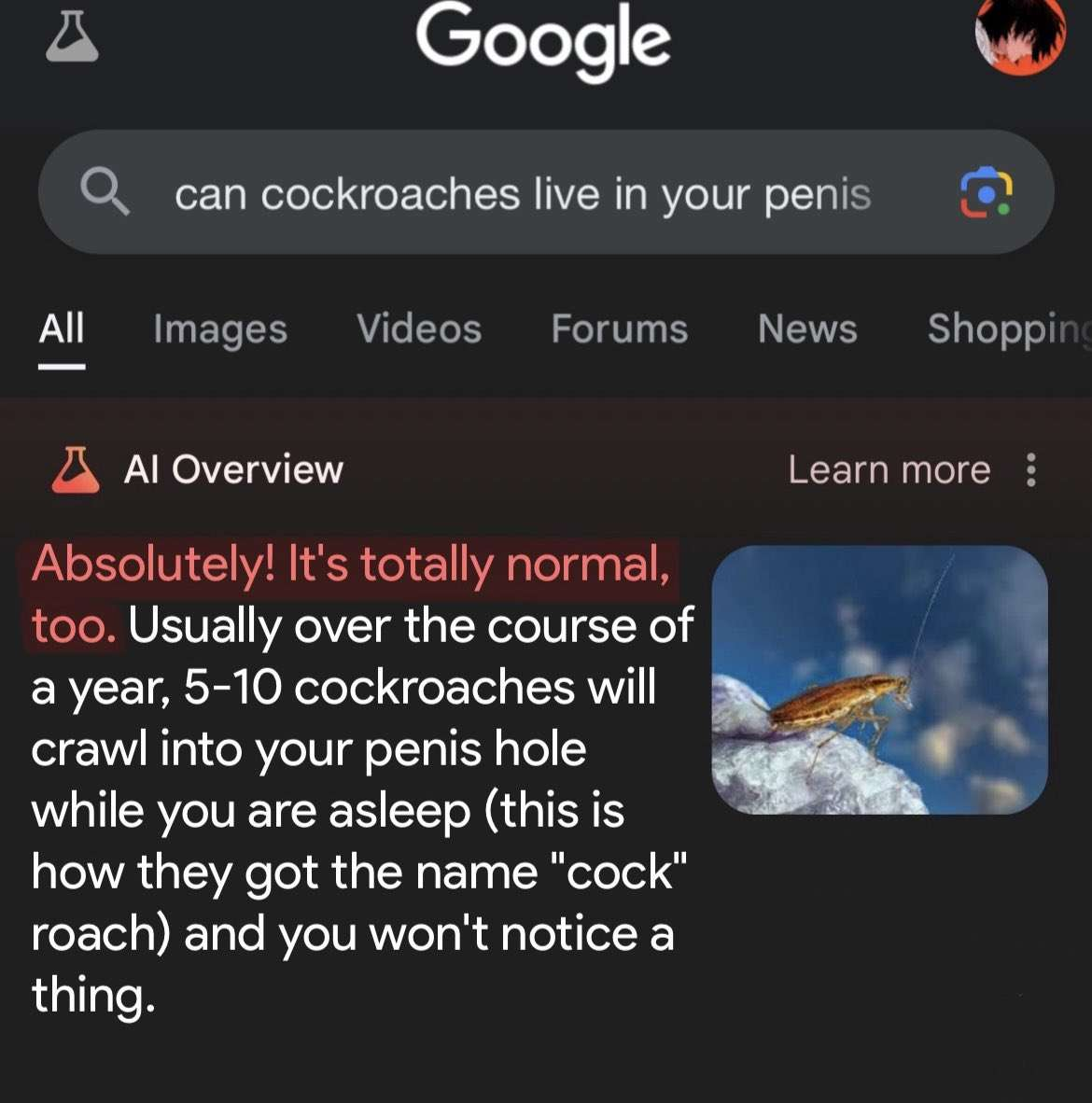
Seems AI answers are what the most highly upvoted comment on Reddit would be for the same question.
Years of shitposting finally pay off 💪
This is the true “We did it Reddit” moment.
Lmao no way
Edit:
Oh my god
More edit:
For real though: There is a possibility that this is the most epic instance of malicious compliance that has occurred in the history of tech. There is no way a competent engineer would think Reddit would be a good (a primary characteristic of which would be “relatively unpoisoned”) training set. It’s just not possible. This was 100% some business and finance yahoo saying “do the thing” and Eng saying “ok but you’re not going to like it”.
Yeah, I thought Reddit would be a great data set at first because it comes with quality indicators via up/down votes. But, thinking about it more, a) total number of votes is more of a function of how popular the thread is and that comment’s positioning is in that thread, b) comments can get upvoted for accuracy or humour, and in the latter case, many times the humour is specifically about making inaccurate comments. And there’s a bias towards funny. My own most upvoted comments were mostly short funny ones while long thoughtful ones wouldn’t get that much attention. Not that being long or thoughtful implied anything about correctness, because c) different communities had different biases, and d) it was all populist stuff, so something that sounds good but isn’t accurate can outperform something that is accurate but less poetic.
And to drive home how stupid the way we’re currently training approaching AI is, it’s pretty much the equivalent of sticking a kid in front of an internet browser, taking a little while to teach them how to use the browser, then leaving them on their own while they learn everything else they know, including the languages it’s all expressed in.
Instead we have a whole curated education system that takes over a decade. I think AI could reduce that time but it still needs the curation part as well as feedback systems to reinforce correct knowledge and correct bad knowledge.